
旦用难回!鸿蒙系统的多设备分发和跨端流转,用起来真香
近日的华为开发者大会2022(Together)上,鸿蒙系统带来的惊喜体验着实不少。跨端协同能力一直是它的一大亮点,而且随着鸿蒙系统终端设备用户量的快速增长,华为还在不断发掘跨端能力的更多应用场景和玩法,比如服务多设备分发和跨端流转这两大新功能,就给用户带来极大便利。
多设备分发,提升服务的曝光和流量
这次我收到的HDC通知信息是一种美观易读的卡片,了解到原来是华为利用智能极速渲染技术将信息中的关键内容自动生成,只要点击信息卡片下端的“服务”按钮,即可跳转查阅大会指南和会务信息,未来智能信息即将成为一种全新的服务入口。

借助HarmonyOS的跨端能力,原子化服务的另一大优势是帮助服务实现多设备分发,提升服务的曝光和流量。
拿小编天天都在用的华为音乐举例,一首歌曲在华为手机、智能手表、智慧屏和问界系列汽车的智能座舱里都能畅听。早上在家一边听音乐一边吃早餐,出门开车上班,音乐会自动流转到鸿蒙车机上,无需额外操作,想在哪儿听就在哪儿听。

而且,这对于音乐创作者们来说也是一件好事,可以让更多人接触到他们精心创作的好作品。华为开发者大会期间公布了一个有趣的数据:深受乐迷喜欢的治愈系钢琴曲《继续蜕变》,最早只在华为音乐上可以听,在座舱、手表、智慧屏等多种设备同步上线之后,分发量增加了接近一倍。而且小编还了解到,华为音乐还跟全球的版权伙伴展开了深入合作,今年支持多设备播放的曲库量新增了超过1100万首,相信以后这个数字还会不断增长。
值得一提的是,针对近些年深受大众欢迎的国风音乐人,华为还推出了特别的扶持项目——“鹿蜀计划”,给到这些优质音乐人更多的流量扶持和曝光机会。比如米库喵、韩帅、吴佩霄、天童乐队、周典奥等一大批年轻音乐人就获得了华为音乐的特别支持,他们的上千首作品都在华为音乐上架了。其中《山水谣》和《王朝》等近百首获奖作品都获得了多设备、多场景下的亿级分发曝光资源,不仅让更多用户领略到了国风音乐的魅力,弘扬了传统文化,也让国风音乐人享受到了“全场景”流量红利,可谓一举多得。
服务也能跨端流转,自驾游路线不再愁
更令人惊喜的是,HarmonyOS的跨端能力不仅能让原子化服务在多设备上分发,还支持服务的跨端流转。比如在这次开发者大会上亮相的路书服务就相当惊艳。这项服务是Petal Maps和携程联合提供的。
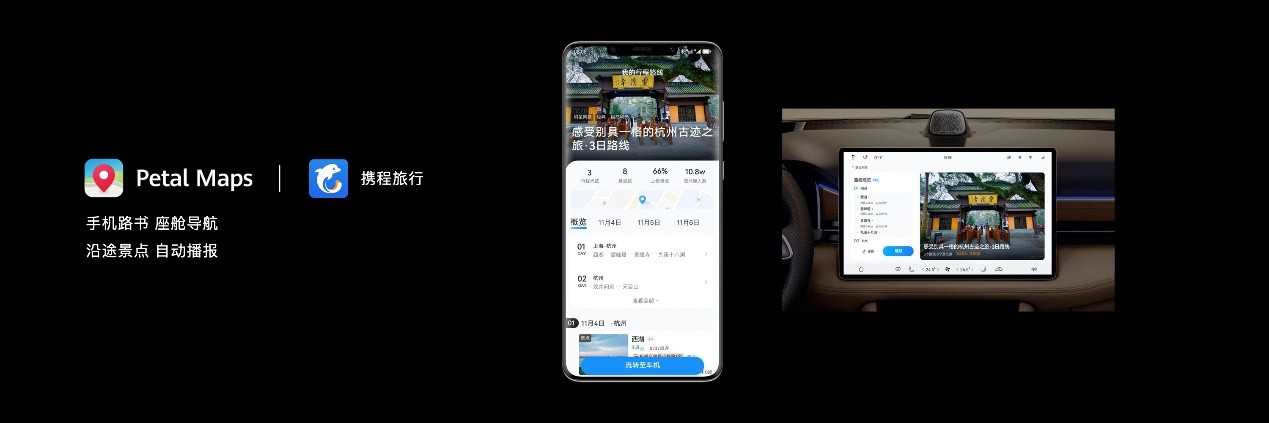
以往我们要自驾出游,会先在手机上的旅行APP里查询各种攻略,再制定路线,想要前往目的地或者中途想去哪个景点,都要做好详细的规划。现在有了服务跨端流转功能就方便太多了。我们可以把路书里的旅行路线流转到问界系列汽车的智能座舱,确认路线后就会直接拉起Petal Maps导航,并将途经景点自动设为导航途经点。而且快到景点时,还能自动播报景点介绍,展示景点相关信息。有了这么方便的路书服务和跨端流转功能,以后再也不用因为做自驾游攻略而发愁了。
而且根据华为开发者大会上的消息,除了路书之外,现在还有加油充电、美食景点、洗车天气、旅游自驾、快递资讯、代驾救援等等原子化服务都已经登上了问界系列汽车的智能座舱,这些可都是驾车出行高频应用场景,可以说是相当人性化了。以目前鸿蒙系统的用户增速和影响力来看,估计很快就会有更多支持跨端流转的服务进入汽车座舱了,值得期待。
除了小编今天提到的服务多设备分发和跨端流转之外,这次华为开发者大会上公布的亮点功能还有很多,大家不妨在日常使用中多多发掘鸿蒙系统这座“宝藏”。小编也希望鸿蒙系统能够越来越好用,在未来带给我们更多惊喜。
文章来源:品玩
来源:业界供稿
好文章,需要你的鼓励


CIO有效管理影子AI的六大策略
随着员工自发使用生成式AI工具,CIO面临影子AI的挑战。报告显示43%的员工在个人设备上使用AI应用处理工作,25%在工作中使用未经批准的AI工具。专家建议通过六项策略管理影子AI:建立明确规则框架、持续监控和清单跟踪、加强数据保护和访问控制、明确风险承受度、营造透明信任文化、实施持续的角色化AI培训。目标是支持负责任的创新而非完全禁止。

NVIDIA推出OmniVinci:让AI同时拥有眼睛、耳朵和大脑的突破性进展
NVIDIA研究团队开发的OmniVinci是一个突破性的多模态AI模型,能够同时理解视觉、听觉和文本信息。该模型仅使用0.2万亿训练样本就超越了使用1.2万亿样本的现有模型,在多模态理解测试中领先19.05分。OmniVinci采用三项核心技术实现感官信息协同,并在机器人导航、医疗诊断、体育分析等多个实际应用场景中展现出专业级能力,代表着AI向真正智能化发展的重要进步。

英国推出DaRe2THINK平台助力全科医生参与临床试验
英国正式推出DaRe2THINK数字平台,旨在简化NHS全科医生参与临床试验的流程。该平台由伯明翰大学和MHRA临床实践研究数据链开发,能够安全传输GP诊所与NHS试验研究人员之间的健康数据,减少医生的管理负担。平台利用NHS现有健康信息,安全筛查来自450多家诊所的1300万患者记录,并使用移动消息系统保持试验对象参与度,为传统上无法参与的人群开辟了研究机会。

Salesforce发布BLIP3o-NEXT:图像生成与编辑的新突破
Salesforce研究团队发布BLIP3o-NEXT,这是一个创新的图像生成模型,采用自回归+扩散的双重架构设计。该模型首次成功将强化学习应用于图像生成,在多物体组合和文字渲染方面表现优异。尽管只有30亿参数,但在GenEval测试中获得0.91高分,超越多个大型竞争对手。研究团队承诺完全开源所有技术细节。
2022
11/09
10:58
分享
点赞

CIO有效管理影子AI的六大策略
英国推出DaRe2THINK平台助力全科医生参与临床试验
OpenAI与谷歌解读AI如何重塑市场营销策略
帕洛阿托将为你揭示未来科技发展趋势
Belkin最新MagSafe充电产品实测体验
迪士尼与AI动画的新现实:瞬间生成30万个动画姿态
AI偏见问题已被证实存在但模型"承认"无法证明什么
数字化时代职场转型指南:三大核心能力助力职业发展
Sora负载过重限制用户生成:OpenAI面临GPU熔毁警告
Snap用户将破10亿,Meta推新XR应用,多项AI技术迎来突破
KDE Plasma设定日期彻底弃用X11,Wayland推进加速
PostHog承认Shai-Hulud 2.0是其历史上最严重的安全事件
