
华为发布全球首个多语种权威知识检索生成模型WebBrain
11月4日,华为开发者大会2022(Together)在东莞松山湖开幕。华为在大会中正式推出全球首个多语种权威知识检索生成模型——WebBrain。基于领先的AI能力,WebBrain在知识洞察助手、搜索问答、辅助阅读等语义理解生成的场景中,能够为用户带来更为精准权威的搜索体验,帮助用户更方便地获取知识和信息。
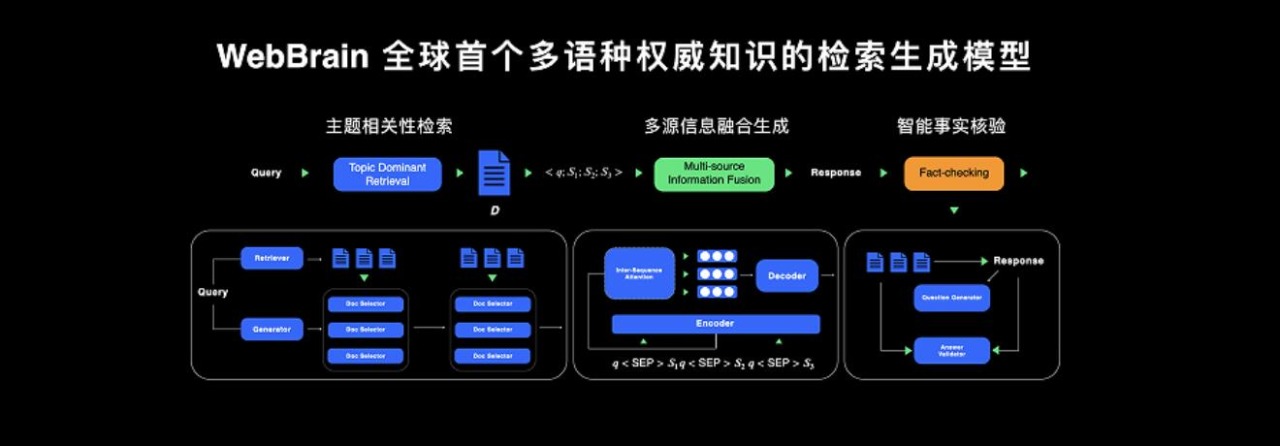
当下信息过载时代,如何精准检索到想要的信息成为一大难题,特别是针对复杂问题的搜索,要想获得完备和权威的解答则更是难上加难。WebBrain通过检索增强技术和自然语言生成技术实现端到端的权威知识的搜索与生成。具体来说,该模型通过“主题相关性检索” 、“多源信息融合生成”、“智能事实核验”三个关键步骤,最终为用户带来权威完整的“答案”,有效解决了海量信息时代信息检索难的痛点,大大提升检索质量和效率。
作为检索过程中的第一步,“主题相关性检索“可在千亿网页中精准搜索到用于生成高权威性答案的网页证据和片段,以用于提升生成模型的效果;对于搜索到的文档,“多源信息融合生成”能够突破输入长度限制,对检索文档去粗取精,从而实现高质量片段引用;最后,“智能事实核验”则可针对生成的答案,包括内部链接及外部文档引用,进行相关性、权威性、完备性多方面核验,再以自然语言的方式输出结果。WebBrain检索生成模型可从中文、英文、西语等多个语种的网站中进行检索,并自动翻译成你所需的语言呈现。
当应用WebBrain模型对一个问题搜索时,我们可以直接获取一个准确、清晰、完备的结果,这将极大改变我们获取信息、研究、以及生产作业的效率。华为阅读正在集成该技术,用户在阅读过程中可随时对感兴趣的点进行实时搜索,WebBrain会自动查找与整理全网内容,并以一定的逻辑结构为用户提供相关知识,辅助用户进行延展阅读。WebBrain很好地解决了对于复杂问题搜索难的问题,有效提升了阅读体验,让“信息检索”这件事变得更加简单。
来源:业界供稿
好文章,需要你的鼓励


IBM大型机本月获得Spyre AI加速器升级
IBM Spyre加速器将于本月晚些时候正式推出,为z17大型机、LinuxONE 5和Power11系统等企业级硬件的AI能力提供显著提升。该加速器基于定制芯片的PCIe卡,配备32个独立加速器核心,专为处理AI工作负载需求而设计。系统最多可配置48张Spyre卡,支持多模型AI处理,包括生成式AI和大语言模型,主要应用于金融交易欺诈检测等关键业务场景。

加拿大女王大学:开源AI生态系统中的“版权炸弹“即将引爆?
加拿大女王大学研究团队首次对开源AI生态系统进行端到端许可证合规审计,发现35.5%的AI模型在集成到应用时存在许可证违规。他们开发的LicenseRec系统能自动检测冲突并修复86.4%的违规问题,揭示了AI供应链中系统性的"许可证漂移"现象及其法律风险。

Ganiga将在TechCrunch Disrupt展示AI垃圾分拣机器人
意大利初创公司Ganiga开发了AI驱动的智能垃圾分拣机器人Hoooly,能自动识别并分类垃圾和可回收物。该公司产品包括机器人垃圾桶、智能盖子和废物追踪软件,旨在解决全球塑料回收率不足10%的问题。2024年公司收入50万美元,已向谷歌和多个机场销售超120台设备,计划融资300万美元并拓展美国市场。

语音识别遇上“扩散大脑“:剑桥-清华-伊利诺伊团队让机器听得更准确
这项由剑桥大学、清华大学和伊利诺伊大学合作的研究首次将扩散大语言模型引入语音识别领域,开发出Whisper-LLaDA系统。该系统具备双向理解能力,能够同时考虑语音的前后文信息,在LibriSpeech数据集上实现了12.3%的错误率相对改进,同时在大多数配置下提供了更快的推理速度,为语音识别技术开辟了新的发展方向。
2022
11/07
10:24
分享
点赞

SAP Business Suite 整合 AI、数据和应用,驱动下一代企业转型
API安全:守护智能边缘的未来
Solidigm 成立AI中央实验室,配备高性能、大密度存储测试集群
智慧城市的绿色引擎:从楼宇到数据中心的可持续之路
IBM大型机本月获得Spyre AI加速器升级
Ganiga将在TechCrunch Disrupt展示AI垃圾分拣机器人
新加坡昇菘集团获批自动驾驶车队运营供应链
思科新路由器将分散数据中心整合为AI训练集群
CoreWeave推出无服务器强化学习平台降低企业AI成本
当年只有30人在训练AGI:Anthropic预训练负责人访谈的万字实录,曾经的AI实验室都是通才,现在大家都是专才
NBA中国与阿里云宣布达成多年合作,重塑球迷互动体验
PEC 2025 AI创新者大会年度提问:新工作时代:AI工作流由谁主导?
